
Bulk insert array of JSON objects into Azure SQL Database using Microsoft Flow
3 March 2019Following on from my previous post, Export Time Entries from Harvest using Microsoft Flow, I ended up with an array of time entries objects and now I need to store it all away in an Azure SQL table.
The easiest approach would be to utilise an Apply to Each action to loop over all of the entries pulled from the Harvest API and in each loop use the Insert Record action to add a new item to the table.
Whilst this works, the Apply to Each is slow and when dealing with thousands of records, you don’t want to be executing individual requests to insert each row. Where possible, you should always try to avoid using the Apply to Each action to keep your Flows performant (see Removing unnecessary Apply to Each action when using Get Items action).
So how do we add thousands of rows quickly and without using a loop? The answer lies with Azure Blob Storage and a SQL Stored Procedure.
I created an Azure Storage Account called ‘harvestdata001’ and a blob container called ‘harvestdata’, this is be where the array containing the time entry objects will be saved to as a JSON file. This is done easily by using the Create blob action in Flow, passing the array as File content, giving it a filename and choosing an appropriate path, ‘harvestdata’ being the root of the blob container.
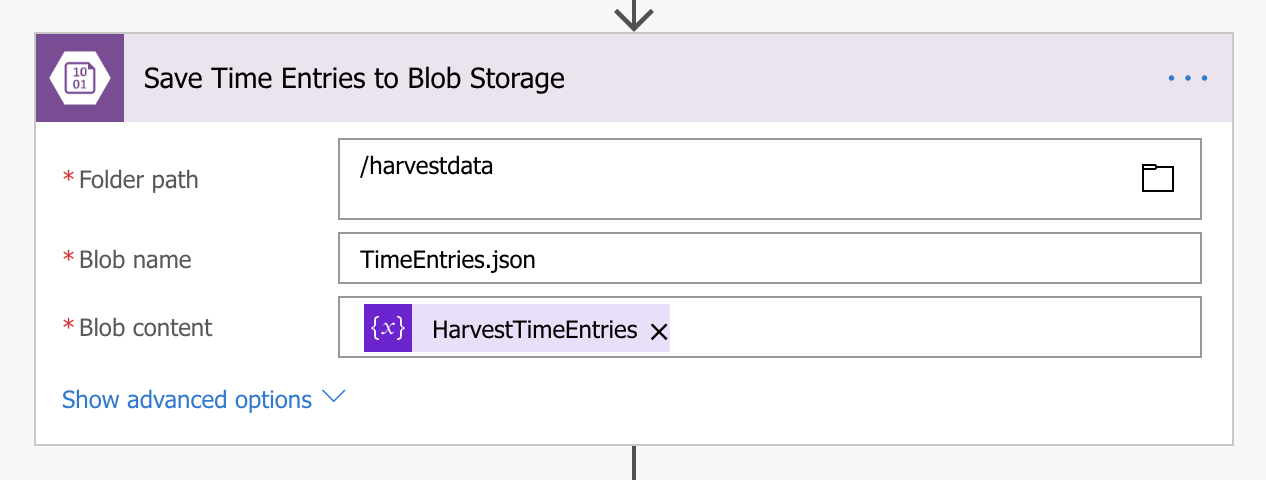
Now that I have the data stored where I need it, I then set about configuring Azure SQL so that it knows where to look.
Executing the above SQL against the database, it does a number of things, it configures a master password for the database (this is required to create the credential and external storage), an external datasource credential and the external datasource itself which is associated with the credential created in the previous statement. In SQL Server Management Studio, you can see the external storage under External Resources.
The next step is to create the stored procedure which will handle the importing of data.
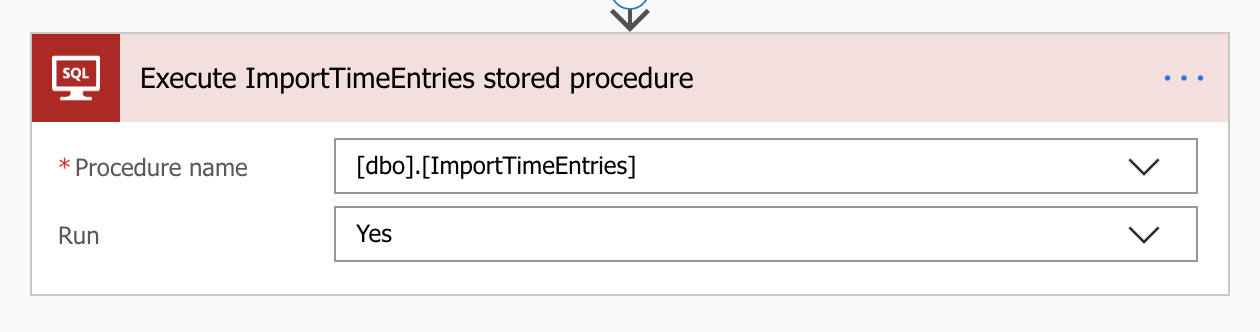
Executing the above SQL against the database creates a new stored procedure called ImportTimeEntries, it accepts single parameter called Run which expects the number 1 to be passed, otherwise it doesn’t run, this reason for this will become apparent later.
In my scenario, this stored procedure also truncates the time entries table and then imports all the data from the external storage, not the most elegant of solutions but serves its purpose (for now 😀).
After the truncate statement is where the real magic happens, the FROM statement loads the JSON file from Azure Storage and the WITH statement creates an in-memory resultset, each row defining the column name, data type and an expression which maps property in the JSON to the column, this is particularly useful when the JSON property name does not exactly match the column name in your SQL Table.
The in-memory resultset is then used as the data source for the SELECT and INSERT statements to add the rows to the TimeEntry table.
Moving back to Flow, all I needed to do was to add a new action, using the Execute Stored Procedure action I execute the ImportTimeEntries procedure. Here is where the Run parameter was needed, not sure if this is a bug or by design but Flow doesn’t like it if you try to execute a stored procedure without passing a parameter.
As I mentioned at the start of this post, the reason for doing all of this was for performance.
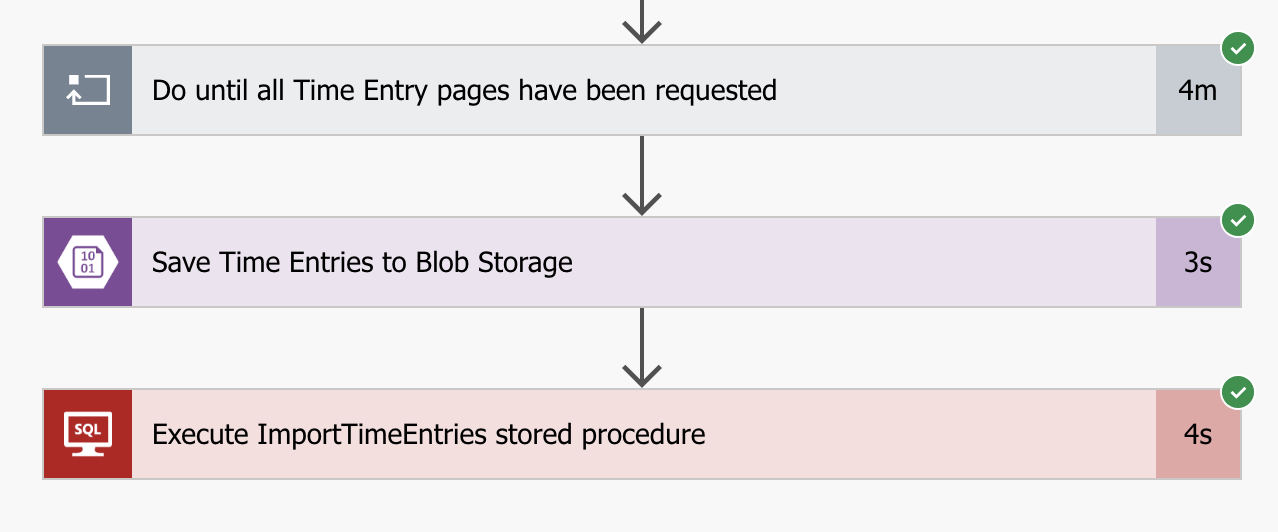
It takes 4 minutes to pull all the time entries from the Harvest API, thats 3993 rows but it takes only 4 seconds to transform and import all of that data into SQL. Impressive! 😀